A la vista de que la próxima nueva versión LTS está a punto de salir (Asterisk 18), hace algún tiempo hablaba con un compañero sobre las razones por las que muchos usuarios habían continuado utilizando versiones obsoletas (Asterisk 1.8 y Asterisk 11 principalmente) en lugar de «abrazar» las nuevas versiones Asterisk 13 o Asterisk 16.
Se nos ocurrieron algunas posibles razones, aunque nuestras razones son muy personales orientadas principalmente por el trabajo que normalmente hacemos y las particularidades que pueden tener. Por esta razón, se nos ocurrió preguntar a los usuarios de Sinologic, de forma anónima, qué versión de Asterisk utilizan frecuentemente y en caso de que no sea la última posible y quiera participar, las razones que hay detrás de utilizar estas versiones.
Así que si os apetece participar en esta breve encuesta de 4 preguntas, (en la que tardaréis apenas 20 segundos) próximamente analizaremos y publicaremos los resultados obtenidos, estamos seguros que a más de uno le sorprenderá bastante.
Como cualquier campo técnico que se asienta y madura, aparecen siempre personas, profesionales y empresas que tienden a avanzar en el desarrollo de cualquier mínima categoría, especialidad y variación de dicho campo con el objetivo de crecer, conseguir nuevos clientes o ampliar beneficios.
Esto ha ocurrido siempre, y ocurrió en el mundo de las bases de datos, cuando toda la información se almacenaba en archivos de textos, luego se pasó a almacenar en archivos binarios para poder disponer de un método de búsqueda más rápido y eficaz (¿alguien se acuerda de DBASE III Plus y similares?) luego aparecieron «motores» que ayudaban a organizar y realizar búsquedas en esos ficheros y cuando todo parecía que estaba inventado con la aparición del Access, MSSQL, MySQL, PosgreSQL y Oracle… apareció una nueva ramificación con los NOSQL que dió lugar a una nueva forma de entender las bases de datos (Mongo, Redis, Cassandra…). Estos motores no sustituyen a los primeros, si no que forman una especialización del motor para cierto tipo de información (más voluminosa, menos relacionada, ideal para grandes cantidades de datos y búsquedas muy rápidas y simples…) y si uno pensaba que ahí acababa la cosa, aparecen los motores de bases de datos orientados a «series de tiempo» (TimeSeries), ideal para guardar grandes volúmenes de información prestando especial interés a cuándo se insertó esa información. Esto es ideal y específicamente creado para IOT, telemetría de todo tipo (desde servidores hasta coches) y un largo etcétera… y como siempre, todo tiende a expandirse y especializarse hasta el infinito.
Lo mismo que le ha ocurrido a las bases de datos, ocurre hoy día en cualquier campo técnico: programación, robótica, comunicaciones, criptografía, cyberseguridad, etc. Cualquier entendido de hace 10 años en cualquier tema técnico, que no haya evolucionado con los continuos avances, hoy día no sabría ni por dónde empezar con la cantidad de modificaciones y ramificaciones que ha dado su especialidad.
En la VoIP por supuesto, también ocurre… desde los inicios en los que nos bastábamos para crear un sistema central basado en Asterisk y un conjunto de teléfonos con 4 o 5 servicios estándar (tranferencias, desvíos, BLF, etc.) hoy día todo se especializa en cualquier ámbito donde la VoIP tenga una importancia crítica e importante: Kamailio u OpenSIPs en proveedores de servicios, Asterisk o FreeSwitch para centralitas básicas a las que se le acopla generalmente un interfaz de gestión para dotarla de características para callcenters, centralitas virtuales, o simplemente para instalar en una empresa y que la telefonía funcione perfectamente con sus teléfonos IP de toda la vida.
Los teléfonos han evolucionado muchísimo, desde los antiguos Kimpo, Sipura, BT100 o Swissvoice, pasando por los Thomson ST2030, Linksys o Polycom hasta los últimos modelos con pantalla táctil, a color con todo tipo de leds, sensores, indicadores y funciones como los últimos modelos de Snom, Grandstream, Audiocodes o Yealink. Teléfonos para todos los gustos pero imposible comparar los antiguos modelos con los nuevos, no únicamente en prestaciones si no en apariencia.
Y aún así, esta metodología de funcionamiento, que podría considerarse tradicional o estándar y que seguramente sea la más frecuente de encontrar en las empresas por su relación calidad-precio-estabilidad, choca con una nueva ramificación de la VoIP que lleva gestionándose más de 10 años y que, al igual que ocurría con el mundo de las bases de datos, crea un nicho muy específico, aunque bastante amplio, que consiste en atraer la VoIP directamente de la aplicación/web/… y es WebRTC.
WebRTC no sustituye inicialmente a una centralita y sus teléfonos, su función es mucho más a bajo nivel y todo depende de la aplicación que gestiona las llamadas y las conversaciones, depende de la empresa que lleva la aplicación, y de que la aplicación esté actualizada. Una empresa que opte por un sistema WebRTC no necesitaría teléfonos IP, ni posiblemente un Asterisk que gestione esas llamadas, ya que la mayoría de las aplicaciones WebRTC están orientadas principalmente a interactuar entre usuarios de la misma plataforma. Como ejemplo tenemos a Whatsapp, Telegram, etc. que como bien se puede comprobar, no se puede hacer una llamada a un número fijo o un número internacional, ya que únicamente admite llamadas entre usuarios de la plataforma. El día que la plataforma deje de funcionar, la aplicación no tendrá opción para que podamos utilizar otra plataforma diferente a la oficial.
Esto no siempre es así, hay empresas que buscan integrar un sistema híbrido: mitad SIP, mitad WebRTC o lo que viene siendo utilizar un softphone WebRTC para conectar con la centralita Asterisk de toda la vida como si fuera un softphone más. Realmente esta idea es muy interesante para muchas empresas, aunque no es el objetivo de WebRTC por lo que tampoco hay mucho interés en ofrecer esta solución.
El objetivo de WebRTC es traer la posibilidad de comunicarse directamente a la aplicación y que el usuario que está trabajando en dicha aplicación, pueda hablar con otras personas (compañeros, clientes que se conectan a la web, etc.)
Así trabajan otras empresas como Microsoft Teams (antes Skype$Bussiness, antes Lync, antes OCS, antes …) favoreciendo y acercando la comunicación interna a través de una comunicación WebRTC y (si contratas el módulo PBX) poder conectar una PBX compatible para poder hacer y recibir llamadas empresariales puntuales.
Personalmente no me imagino a un callcenter trabajando con Microsoft Teams, tanto por el coste mensual, como por las limitaciones funcionales de la PBX y como por el coste de actualización cada pocos años de todo el sistema de comunicaciones, de la misma manera que tampoco me imagino un sistema de multivideoconferencia gobernado por un Asterisk en la que cada participante tenga que configurar su aplicación de videosoftphone para poder conectarse e interactuar.
Después de muchos años, WebRTC no es una evolución de la VoIP, si no una ramificación que aporta unas soluciones muy concretas a unos problemas que la VoIP tradicional: la de la PBX -register-proxy-usrloc-etc.- y los teléfonos IP no puede dar. Hay quien trabaja para crear una integración SIP-WebRTC, de la misma manera que hay motores de bases de datos NoSQL que admiten sentencias SQL y unas pseudo-relaciones bastante curiosas, pero desde mi punto de vista, el mundo «SIP» y el mundo «WebRTC» son dos ramas del mismo árbol que sirven a propósitos distintos y no del todo incompatibles.
Hay que tener en cuenta que Asterisk 17 soporta SIP bajo WebSocket, lo que permitiría conectar clientes WebRTC (siempre que sepas, puedas y tengas tiempo para programar un cliente WebRTC).
Por supuesto, aún no ha salido un sistema que integre ambos conceptos de forma nativa y es que los requisitos de WebRTC (FQDN, HTTPS, navegadores últimas versiones, etc.) hacen difícil una integración LTS (sin apenas necesitar de un mantenimiento mensual) por lo que quien opta por un sistema WebRTC debe estar dispuesto a pagar un mantenimiento continuado de programación para que el sistema siga funcionando pese a las variaciones de los navegadores, algo que muchas empresas no están dispuestas a hacer.
En resumen: La VoIP sigue expandiéndose, lentamente (eso si) hacia otras formas de comunicarse utilizando la web, y aunque veamos que el WebRTC es lo más de lo más, no hay que olvidarse que la VoIP basada en SIP, con sus teléfonos IP, sus centralitas software y hardware, sus paneles de gestión y monitorización, sigue existiendo, sigue avanzando y sigue siendo hoy día la opción más utilizada por las empresas. Quizá eso varíe en un futuro a medio o largo plazo, pero no será pronto.
Por mucho que pase el tiempo, y más ahora que el número de sistemas VoIP en la nube (o en remoto) aumenta, el número de ataques también aumenta considerablemente y es entonces cuando se hace necesario el uso de herramientas que nos ofrezcan la seguridad que necesitamos para poder estar seguro que nuestro sistema está controlado y no vamos a ser víctimas de un ataque mientras no estamos pendientes. Esta es la función de SIPCHECK, una herramienta que se conecta a Asterisk y vigila de accesos ilegítimos de direcciones IP desconocidas manteniendo nuestro Firewall actualizado con las direcciones IP de los atacantes.
En 2010, durante una comida en el curso de Asterisk Advanced de Bilbao, surgió una idea muy simple pero efectiva. Uno de los principales problemas que tenían muchos de ellos era la inseguridad que producía recibir ataques en los Asterisk que debían estar expuestos por Internet.
Ni que decir tiene que surgieron muchas ideas: utilizar VPN, cambiar a puertos no estándar, etc. y tras la exposición de los problemas y las posibles soluciones, una de ellas se presentó tan sencilla como fácil de implementar: Generar una aplicación que analizara el log de Asterisk y cuando detectara errores de autentificación, baneara automáticamente esa IP compartiendo dicha IP con el resto de la comunidad.
Esto fue una gran idea y así se hizo en la versión inicial de SIPCheck. Cuando el sipcheck detectaba un ataque, obtenía la dirección IP y la compartía con el resto de la comunidad para que todos pudieran tomar nota y rechazarla en los firewalls.
El resultado de esto fue algo más inesperado de lo que pensábamos: miles de direcciones IP baneadas (incluso algunas legítimas) y firewalls con tablas inmensas que incluían direcciones IP que, en algún momento del pasado atacaron a alguien. Estaba claro que tener un firewall con decenas de miles de direcciones IP que, en algún momento pudieron ser víctimas de un ataque y sirvieran de proxy para otro atacante no era la solución, ni siquiera para tenerlo en una tabla ACL de «IPs denegadas» ya que el 90% de esas direcciones IP no van a volver a atacarnos. La solución a esto, sin duda, era otra.
Ante esto, sucedieron varias modificaciones (añadir IPs con un registro de fecha y hora para que expiraran pasado un tiempo, introducir únicamente aquellas direcciones IP comunes que hayan sido baneadas por varios usuarios distintos, etc.) y los resultados fueron interesantes, aunque seguía sin obtenerse el resultado esperado.
Para ello, en 2014 se publicó SIPCheck 2, una versión nueva que incluía un registro sobre las direcciones IP baneadas en una web local que se podía consultar y añadir o eliminar aquellas IPs en tiempo real. Se eliminó la parte comunitaria ya que entendimos que si a un usuario de Japón le ataca una IP, no tiene por qué atacar a otro de Nápoles y, de esta manera se reducía el número de direcciones IP en el firewall. Se añadió soporte IPSet que mejora el funcionamiento de grandes listas de direcciones IP baneadas y aún así, la lista seguía sin ser efectiva (seguían apareciendo nuevas direcciones y seguíamos teniendo en el firewall direcciones que ya no se usaban). Al menos con SIPCheck v.2 podíamos eliminar manualmente aquellas direcciones antiguas.
Es en 2019 que, tras algunos cambios y nuevos proyectos surgió la idea de renovar el SIPCheck para paliar algunos defectos del SIPCheck inicial (que todavía hay gente utilizándolo) así como para reducir la carga al mínimo (muy inferior al de SIPcheck 2 y por supuesto al de Fail2Ban), empezamos a desarrollar la tercera versión nuevamente pero con todas las mejoras.
SIPCheck v.3
Funcionamiento
Esta versión de SIPCheck utiliza dos mecanismos diferentes para controlar los eventos: – Mánager de Asterisk: (el 99% de los ataques) Con esto se controlan los intentos de login erroneos, los correctos y gracias a esto evitamos sobrecargar el sistema cuando el Asterisk es muy grande y genera mucha información en el log. – Archivo /var/log/asterisk/messages: (el 1% restante) Con esto se controlan los INVITES sin autentificar y que no aparecen en el manager. Está claro que con el parámetro ‘allowguest = no‘ ni siquiera aparecerán estos INVITES, pero de alguna manera había que controlar este caso.
El funcionamiento de esta versión se basa en la gestión automática de 3 listas:
Lista blanca : con direcciones IP confiables y que no deben estar baneadas aunque se reciban peticiones de registro con contraseña erronea. (Esta lista blanca la formarán aquellos que incluyamos en el archivo ‘whitelist.txt’ y aquellas direcciones IP que se hayan registrado correctamente.)
Lista de sospechosos : con direcciones IP procedentes de algunos ataques pero no los suficientes como para considerarlos ataques. Cuando se recibe un intento de registro con una contraseña inválida, se almacena aquí hasta que el número de intentos supere un número determinado /y configurable/. Si un sospechoso deja de enviar los intentos, el sistema lo eliminará de la lista de sospechosos pasado un tiempo.
Lista negra : con direcciones IP oficialmente considerados como ataques. Estos son auténticos atacantes y cuando están en la lista negra, el SIPCheck también lo incluye en el firewall impidiendo volver a acceder al sistema, por lo que el sistema es autónomo y no tenemos que preocuparnos. En esta lista permanecerá un tiempo configurable tras el cual se eliminarán tanto de la lista negra como del firewall, manteniendo a este limpio de atacantes antiguos.
Cuando SIPCheck detecte un ataque procedente de una IP, lo añadirá a la Lista de sospechosos y permitirá seguir recibiendo tráfico. Si recibe varias peticiones idénticas entonces pasará a considerarlo como un ataque oficial y lo añadirá a la lista negra y al firewall impidiendo más tráfico procedente de esa IP.
Si una IP se ha registrado correctamente en nuestro sistema, entonces se considera que esa IP pertenece a alguien «confiable» por lo tanto lo añadiremos a la Lista Blanca durante un tiempo evitando considerarlo atacante durante el tiempo en el que esa IP esté en la lista blanca. Esto impedirá banear una dirección IP de una empresa únicamente porque un teléfono tenga una contraseña errónea.
Todos los valores son configurables: número de contraseñas erroneas, tiempos en cada una de las listas, etc.
Se tiene incluso un archivo ‘whitelist.txt‘ donde podremos indicar las direcciones IP que jamás deberán serán baneadas por el SIPCheck (operadores, IPs de gestión, etc.)
Objetivos
El objetivo de esta aplicación son varios:
Orientado a sistemas de alta carga: Probándolo en sistemas de alta carga, el consumo se disparaba, por lo que había que buscar una forma alternativa de minimizarla. Para ello se utiliza principalmente el ‘manager’ de Asterisk y para algunos casos puntuales el messages como complemento y evitar la sobrecarga de analizar cada línea del log de Asterisk.
Evitar falsos positivos: En versiones anteriores, si un teléfono enviaba varias veces una contraseña erronea, el SIPCheck baneaba la IP entera. En esta versión, si una IP es registrada correctamente, pasa a una lista blanca que impide activar el protocolo de ataque en dicha IP compartida por varios teléfonos, seguramente de la misma empresa. De esta manera evitamos que un teléfono mal registrado en una empresa banee la IP del resto de la empresa.
Persistente en el tiempo: Si se reinicia la aplicación, todos los datos y direcciones IP de todas las listas se mantienen y se vuelven a banear en firewall (si no lo estaban ya).
Configurable: Se ha añadido un archivo sipcheck.conf donde poder configurar prácticamente cualquier parámetro que permita personalizar la aplicación.
La instalación es bastante sencilla ya que tan solo hay que seguir las 4 instrucciones del README para instalarla.
Y para comprobar qué está haciendo, todo queda registrado en un archivo de log en /var/log/sipcheck.log
Con esta aplicación, en varios Asterisk expuestos en Internet a modo de honeypot sin ningún otro tipo de protección, el sistema ha detectado y bloqueado cientos de ataques y lo mejor es que mantiene un firewall bastante reducido ya que las direcciones IP desde donde se producen los ataques dejan de atacar cuando empiezan a ser bloqueadas. Gracias a estos honeypots hemos aprendido muchas cosas nuevas sobre estos ataques que nos permitirán seguir mejorando el SIPCheck para conseguir detectar nuevas formas de ataques.
Si tienes comentarios o quieres dejarnos un feedback sobre esta aplicación puedes escribirnos un issue en Github, un comentario en el canal Telegram de @sinologic o en el correo electrónico sipcheck@sinologic.net
Me va a permitir el lector, aprovechar que estamos empezando el año para compartir una reflexión que he tenido estos días y que seguramente venga a colación de todo el baño de información basada en noticias, comentarios, redes sociales y demás sucesos que ocurren hoy día en el mundo. No me considero una persona puramente «local», de hecho me gusta estar enterado e informado de todo lo que ocurre en el mundo y para ello no sólo me conecto a redes sociales donde sigo a mucha gente con ideas y conocimientos muy diversos, si no que además busco continuamente información sobre aquello que desconozco para poder ampliar mis conocimientos, de ahí que haya visto algunas cosas y me haya animado a escribir algo ajeno a la temática de esa página. (una vez al año, no hace daño) 😉
Tendemos a pensar que todo lo que se publica en Internet quedará para la posteridad, nos negamos a pensar en la necesidad de ponerle una fecha límite, una fecha de caducidad a esa foto o ese artículo que escribimos porque algo en nuestro interior piensa que estará siempre ahí y que, si bien ahora es «actual», dentro de unos años podría ser útil si alguien buscase información y viera lo que escribimos entonces.
Por desgracia, uno de los grandes problemas de Internet tal y como está planteada hoy día es que, el contenido actual funciona tal y como planteamos, pero en contenido antiguo se estropea con el tiempo cual manzana. Quizá puede ser interesante de cara a tener un historial de qué fue lo que ocurrió en aquel momento, en aquel mes de aquel año, pero nos olvidamos de un detalle que lo cambia todo y, como la vejez, algo cambia y no siempre es lo que nos gustaría.
Una de las ventajas inherentes a Internet, una de las cosas más importantes de Internet y que suele pasar desapercibida, es su capacidad para enlazar contenido, saltar de una página a otra a través de enlaces que nos amplía la información sobre cierto contenido y nos invita a profundizar más sobre un tema del que se habla y desconocemos. Por desgracia, al cabo de unos años, esos enlaces no siempre están disponibles, la compraventa de empresas puntocom, los cambios de plataformas, las nuevas directrices en cuanto a SEO y posicionamiento web, están haciendo que Internet cambie su estructura cada cierto tiempo y lo que antes era un enlace a una web de contenidos, ahora sea un mensaje de error de página no encontrada que convierte a ese enlace en algo inútil y vacío en nuestro artículo.
Otro de los problemas es que, al igual que un artículo de calidad puede seguir siendo de calidad con el paso de los años y tiende a ocupar los primeros puestos en una lista de enlaces que aparece como resultado de una consulta en un buscador, no siempre esa página debe ser la primera, y a menudo obtenemos resultados que si bien contienen información relevante sobre los términos que estamos buscando, a veces esas páginas tienen demasiado tiempo y no son relevantes cuando buscamos algo actual.
Por si fueran pocos, además nos encontramos con uno de los problemas más grandes del momento actual, y es que hoy día se genera contenido nuevo más rápido del que se puede almacenar con la tecnología actual, y si bien la capacidad de almacenamiento crece casi exponencialmente y es capaz de guardar toda la información que publicamos hoy día (fotos, vídeos, archivos de datos, grabaciones, audios, etc.) la cantidad de datos que se generan (incluidas las copias de seguridad que duplican o triplican ese espacio necesario), crece exponencialmente mucho más rápido que la capacidad de almacenamiento, y eso tiene dos problemas:
Habrá un momento de colapso que impedirá guardar toda la información que se genere y, por lo tanto habrá que «limitar» el contenido, imagino que a través de un pago por esa capacidad necesaria (si no pagas, no lo guardo) lo que implica que las actuales nubes que almacenan nuestra información de forma gratuita o por un precio mínimo, además de empezar a exigir el pago por guardar nuestra información, también subirán los precios a medida que la información requiera de demasiados recursos. (momento en la que ocurrirá dicho colapso).
El segundo problema es el aumento inconmensurable de información, incapaz de manejar por una persona (hoy día yo mismo tengo tal cantidad de fotografías guardadas que se me hace prácticamente imposible -o muy difícil- manejar) así que imaginémonos dentro de unos años cuando las nuevas generaciones, profundamente digitales se dediquen a guardar datos de cualquier cosa de forma continua (cámaras de grabación continua, datos biométricos que monitorizan cada órgano de nuestro cuerpo y que nos avisan si hay algo que no está bien, generación de datos de intercambio necesarios para hacer simulaciones y adelantarse a nuestros hábitos y así predecir eventos y poder avisarnos, etc.)
Toda esa información, que se crea pero no se elimina, requerirá de un espacio donde almacenarse y un sistema increíblemente costoso de procesamiento que, aunque podamos costeárnoslo nosotros, pagaremos para que empresas especializadas lo hagan y nos eviten tener que instalar un datacenter en nuestra casa con máquinas funcionando 24 horas.
El futuro cercano es apasionante, con muchas novedades que nos facilitarán el día a día, que nos acercan a pasos acelerados a esos nuevos inventos que quedaron guardados a la espera de un momento mejor en el que la humanidad esté dispuesta a aceptar cambios sin escandalizarse, y con una profundidad de información en cada tema que nos interese, tal que convierta la innovación en algo no apto para personas individuales, si no sólo para equipos muy bien engrasados y ágiles.
El futuro lejano en cambio, puede ser algo bastante diferente a lo que tenemos pensado y parecerse más a las distopías de algunas películas, series y libros de ciencia ficción. Pensamos que queda mucho para entonces, pero lo que ocurra en aquel momento será la consecuencia de lo que hagamos en el futuro cercano, dicho de forma alegórica, sembramos ahora los frutos del mañana y por eso es tan importante lo que hacemos en nuestro día a día: qué defendemos, dónde compramos, qué utilizamos, qué ejemplo damos y qué consecuencias tendrá, no solo para el presente, si no para el futuro próximo y el no tan próximo.
Te dedique a lo que te dediques (y entendemos que si visitas habitualmente Sinologic.net es debido a que te sueles dedicar a alguna rama de la tecnología), te habrás dado cuenta que es muy interesante estar al día en cualquier materia que te interese, ya sea por los medios de comunicación, blogs, foros, chats o entre compañeros, muchos de los temas recurrentes son las últimas novedades en este o aquel campo, motivo por el cual nos permite estar al día (o lo más cerca) de lo último en este u otro campo. Si te gustan los móviles, seguramente estés suscrito o visites varias páginas donde se comenten las últimas novedades, rumores y noticias sobre los últimos móviles que van a salir, de la misma manera si te gusta la VoIP, seguramente estés suscrito a ciertas páginas webs, y sigas a determinadas personas y páginas en sus redes sociales para estar más o menos al día de lo que se mueve en este campo.
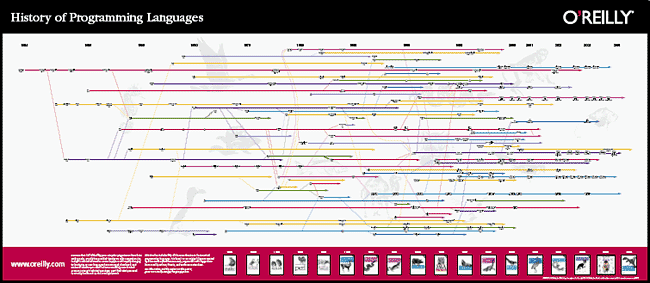
El mundo de las nuevas tecnologías (voy a llamar así a los campos y áreas de la Informática y las Telecomunicaciones), a diferencia de otras especialidades (como psicología, derecho, historia, etc.) no sigue una evolución lineal, si no exponencial. Por ejemplo, si bien en 1960 apenas existían 5 ó 6 lenguajes de programación, entre los nuevos lenguajes que han aparecido, y los diferentes «forks» que han ocurrido de los existentes, hoy día es difícil tener una lista medianamente actualizada de todos los lenguajes de programación que podríamos escoger de cara a desarrollar algo serio. El número de lenguajes crece de forma exponencial mientras hayan personas que los utilicen.
Infografía de los principales lenguajes de programación desde 1950 hasta 2004.
Esto hace que todos y cada uno de nosotros tenga la necesidad/obligación de aprender constantemente, aprender no solo lo que nos gusta, si no también de lo que trabajamos, de lo que hablamos, de lo que tocamos y de lo que somos expertos. No nos vale con «haber aprendido», tenemos que mantener el ritmo de aprendizaje mientras nuestro cerebro nos lo permita, y mantenerlo «ejercitado» dándole de comer conocimiento a medida que vamos «desterrando» aquella información que ya nos nos interese almacenar (a veces es más difícil olvidar que aprender). Hay que hacer este tipo de ejercicios porque uno o dos años apartado de cierta área significa el abandono completo y retomarla podría significar (en según qué áreas) empezar prácticamente de cero. De ahí la importancia de conocer algún método que te permita aprender un nuevo área en el menor tiempo posible para poder retomar «la cima de la ola».
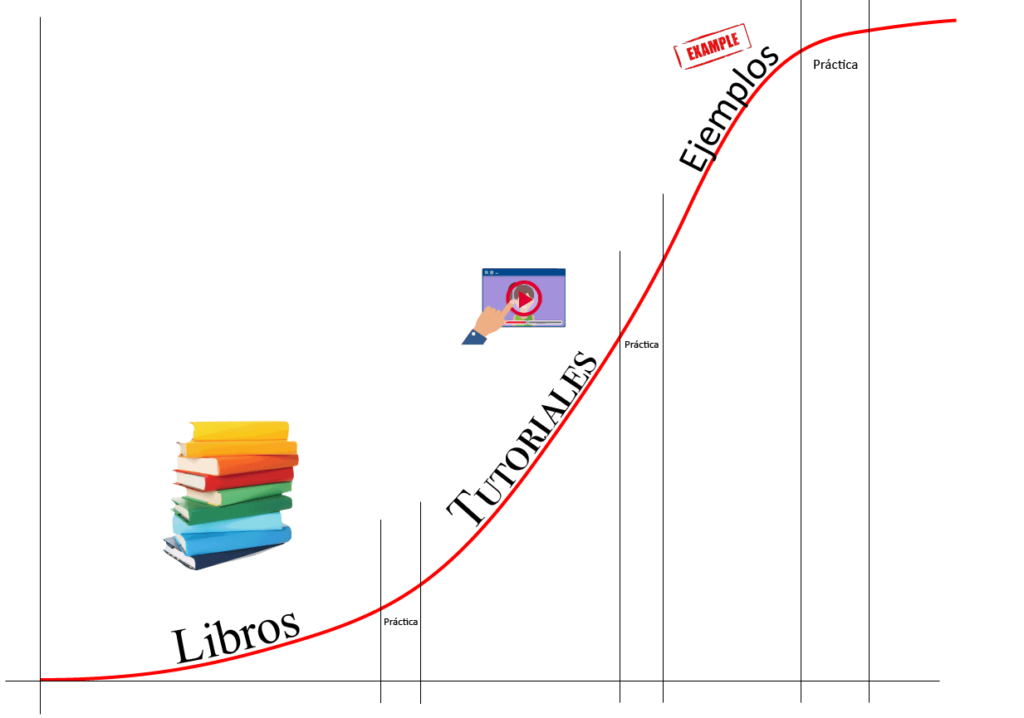
Primer paso: El libro.
En cualquier carrera técnica como ingeniería, lo primero que hacen en cualquier asignatura es proveerte de una lista de libros de consulta. Esto es porque un libro te va a «amueblar» la cabeza para el nuevo concepto que quieras aprender. El libro no tiene porqué ser en papel, puede ser electrónico, pdf o como prefieras, lo importante es lo que transmite, no el medio. ¿Y por qué un libro?. El libro tiene varias características importantes:
Es lo suficientemente extenso como para albergar toda la información importante e imprescindible de ese tema.
Al ser un documento escrito, puedes tomarte todas las pausas necesarias para que tu cerebro procese esa información.
El lector puede consultar cualquier punto del libro en caso de que quiera «recordar» algo que se le esté olvidando.
Por esta razón, una de las primeras formas de aprender algo, es comprar un buen libro y leerlo, desde el principio, hasta el final.
Una vez hecho esto, el aprendiz tiene en su cabeza conceptos básicos. Si ha hecho ejercicios propuestos en el libro, además lo habrá practicado y habrá adquirido entre un 30 y un 50% de lo que haya puesto en práctica, de ahí que sea tan importante continuar con el aprendizaje porque en este momento tendremos una falsa sensación de que sabemos más de lo que realmente sabemos y, aunque estamos preparados para ponernos en marcha y trabajar sobre lo aprendido, tenemos que ser conscientes que aún nos falta un poco más para llegar al nivel que necesitamos.
Segundo paso: Seguir Tutoriales.
En este momento ya deberíamos empezar a plantearnos nuestro primer proyectos, cosas sencillas, cosas que podamos llegar a hacer y que asiente la información que hemos adquirido en el primer paso. A medida que empecemos a desarrollar dicho proyecto, nos daremos cuenta que nos falta información, que el proyecto parecía algo más sencillo en un principio pero necesitamos conocer cómo llegar a hacer ciertas cosas. Este es el momento de tomar dos posibles caminos:
Buscar tutoriales, blogs y páginas donde expliquen cómo hacer ciertas cosas desde un punto de vista de la experiencia que complementen lo que hemos aprendido del libro.
Apuntarnos a un curso que nos enseñe de primera mano y en un tiempo mínimo, toda la información que vamos a necesitar para llevar a cabo nuestro proyecto.
Ambos puntos no son excluyentes, seguramente la idea de asistir a un curso pueda ser un primer paso necesario e importante, pero eso no quita que tendrás que buscar información y tutoriales donde expliquen cómo hacer aquello que necesitas para llevar a cabo tu proyecto.
Considero un error sustituir el libro por el curso, ya que un curso suele servir para «acelerar» la formación, pero no para iniciarla. Fíjese en que he comentado que el libro sirve para «amueblar» la cabeza, y esto es un paso imprescindible para adquirir cualquier nueva información. El cerebro es un órgano muy complejo, del que conocemos muy poco, pero de lo poco que sabemos es que hace falta darle tiempo para poder aprender cosas nuevas.
Un tutorial suele ser un artículo de un blog, un PDF donde se explique cómo hacer algo. Un paso a paso donde se definan, no solo los pasos si no también el motivo de cada uno de ellos. Esa es la principal diferencia de un tutorial y un ejemplo. En el tutorial, si lo seguimos entero (desde principio hasta el final sin saltarnos ningún paso) llegaremos a un objetivo que es lo que veníamos buscando en un principio. Solo para aclarar, un comentario de StackOverflow no es un tutorial.
Tercer paso: Buscar Ejemplos
Una vez hayamos seguido varios tutoriales y hayamos empezado a avanzar en nuestro proyecto, nos daremos cuenta que para continuar, necesitamos ciertas respuestas a preguntas rápidas, es el momento de buscar ejemplos. Estos se encuentran en muchos sitios: Foros, Web de consulta (ahora si, StackOverflow, Github, …), salas de chat o incluso algún comentario de twitter o facebook. En este tercer paso, donde realmente se aprende es viendo el código de otras personas, asistiendo a conferencias y hablando con otros profesionales, aquí no únicamente vamos a responder nuestras dudas (que ya no serán dudas triviales) y además conseguiremos información de primera mano de personas que se han peleado en las mismas batallas en la que estás tú en este momento, además de conseguir una fuente super-valiosa de personas a las que le interesa lo mismo que a ti y que, en un momento dado, podrían ayudarte o trabajar contigo.
Cualquier código (por pequeño que sea), configuración o respuesta es un buen material que nos ayudará a perfilar el conocimiento adquirido y a prepararnos para la cima de la ola.
Cuarto paso: Mantenerse en la ola
Ya hemos visto que lo primero que hay que tener para empezar a aprender, es voluntad de aprender. El esfuerzo para aprender algo es importante, de ahí que debe ser algo que merezca la pena, ya sea porque te gusta, porque trabajes en eso, o bien porque lo necesites como camino para aprender algo, ya que hay ciertas áreas que requieren de conocimientos que hay que adquirir previamente.
Hay ciertas áreas que requieren de leer más libros, quizá menos tutoriales y más prácticas, o incluso hay campos en los que apenas vamos a poder encontrar tutoriales ni ejemplos y apenas unos pocos libros bastante introductorios, ese campo por lo general está poco desarrollado y «la cima de la ola» seguramente se encuentre más accesible.
Aunque parezca mucho esfuerzo (leer libros, buscar proyectos, seguir tutoriales, …) realmente no lo es si hemos seleccionado lo que queremos aprender con pasión, ya que con pasión, cualquier cuesta es menos pronunciada y además, con voluntad y ganas, incluso cualquier curva de aprendizaje, puede realmente ser un bello camino que recorrer, y es que lo bonito de aprender, no solo está en adquirir el conocimiento, si no disfrutar haciéndolo.
Como viene siendo habitual en estas fechas, toca echar la vista atrás y hacer una recopilación de lo que ha sido este año, en cuanto a noticias y eventos ha ocurrido.
Empezamos el año anunciando que una de las grandes de las comunicaciones: Avaya, entraba en concurso de acreedores y su más que posible bancarrota. También comenzamos el año con la presentación de lo que inicialmente fue un fork de Elastix: Issabel, que semana tras semana sigue creciendo con fuerza y que acaban de anunciar su primer año con unas cifras record de descargas y apoyos en un software de comunicaciones.
Kamailio también presentaba su versión Kamailio 5.0 con muchas mejoras con respecto a la anterior versión. Misma filosofía, mucha más flexibilidad, agilidad y potencia para aquellos que trabajan día a día con este software, además de confirmarse la KamailioWorld como uno de los eventos más importantes de Europa en cuanto a VoIP. Igualmente, la comunidad de desarrolladores de Asterisk presentaba en la Astricon la versión Asterisk 15 con muchas novedades y soporte para WebRTC.
El 2017 también pasará por ser el año en el que desapareció el roaming dentro de Europa, permitiéndonos a los europeos utilizar nuestras tarifas de datos y de voz en cualquier país de la Unión. No obstante, nos llevábamos un chasco cuando veíamos que, en cambio, si quisiera llamar a un amigo francés en Francia, iba a seguir pagando llamada internacional hasta 10 veces más caro con el operador de siempre, así que, menos mal que tenemos a los operadores IP para poder seguir hablando sin tener que vender órganos.
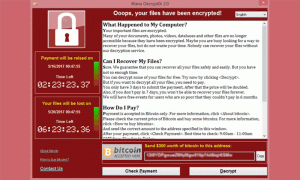
En la seguridad aprendimos que un virus era capaz de poner en jaque en un solo día a medio mundo y a la semana siguiente a la otra mitad. El WannaCry afectó desde servidores hasta simples terminales de supermercados, por lo que nos enseñó (o debería hacerlo) que estar actualizado es algo vital y que eso de quedarnos en versiones antiguas solo puede traernos cosas malas con el tiempo.
Por último, 2017 pasará a la historia como el año en el que los intereses de unos pocos se pusieron por delante de los intereses de muchos, en el que las empresas de telecomunicaciones junto con los gobiernos acabaron con la Neutralidad de la Red, y les permitieron curiosear con lo que se envía y se recibe para poder ofrecerte mejores tarifas y descuentos, lo que viene siendo «vender tu privacidad a cambio de descuentos en tu factura«.
En resumen, 2017 quedará en la historia como un año de estabilización tras los movimientos de años anteriores, un «tocar fondo» y asentarse para empezar a crecer y mejorar en el año que entra. El año en que la IoT entró en la casa mediante frigoríficos, lavadoras o ventiladores. El año del Blockchain, las criptomonedas y su complejo sistema del que todos sabemos que será el futuro, pero que no será fácil de entender.
Sobre el 2018, va a ser un año de cambios, de movimientos estratégicos, de cambios de paradigmas y para muchos, de enfilar a la buena dirección, para otros será un año para crecer y mejorar sus objetivos, pero sea como sea, Sinologic seguirá estando aquí, con algunos cambios que esperemos sean del interés de todos, deseándoos una feliz entrada de año nuevo, que lo celebréis lo mejor que podáis y que disfrutéis todo lo posible cada minuto del nuevo año que entra con vuestros seres queridos.
Como solemos hacer en estas fechas, desde Sinologic os deseamos a todos los lectores, una Feliz Navidad en compañía de vuestros seres queridos, dejando un poco de lado la VoIP (aunque no mucho, de algo habrá que hablar en La Cena de Nochebuena, además de la caída de la cotización del Bitcoin).
A mediados del año 2006 comencé a escribir artículos sobre VoIP, sobre lo que conozco y sobre lo que trabajo, comentarios, opiniones, artículos y tutoriales sobre VoIP, dispositivos, teléfonos, gateways, software y eventos VoIP que considero, son del interés de aquellos que leen estas líneas.
Desde entonces hasta hoy han pasado más de 10 años, escribiendo cuando queremos, cuando tenemos tiempo y cuando hay algo que decir, escribir por escribir solo fomenta la desidia y escribir trivialidades no ayuda a nadie. Trabajamos en el mundo de la VoIP y pese a que este mundo tiene muchas ramas asociadas y muchas cosas que decir, a veces no solo no encontramos tiempo si no palabras para poder explicar las cosas de una forma comprensible para la mayoría.
Sinologic este año está de enhorabuena, cumple 10 años y no podríamos cerrar el año 2016 sin daros las gracias a todos los que leéis estas líneas, a todos los que buscando algo sobre VoIP, añadís la palabra «sinologic» para que aparezcan los artículos relacionados con lo que buscábais, a todos aquellos que nos enseñáis día a día las novedades de la VoIP y nos permitís escribir sobre ellas, a todos… GRACIAS.
La gente de VOZ.COM ha publicado una nueva revista trimestral orientada a un público variado pero interesado en cualquiera de los tres temas principales: Empresas, Tecnología y Comunicaciones, de ahí el nombre de la revista: ETC, un nombre original para una revista que, esperamos, tenga un gran recorrido y sea de interés para todos los lectores.
En sus más de 60 páginas, hay unos artículos de opinión sobre temas dispares, interesantes, variados y llenos de conocimientos que ofrecen una visión diferente de las nuevas tecnologías, una vuelta de tuerca diferente, más meditada sobre un sistema típico de revista, pero con las ventajas de poder leerlo desde cualquier lugar.
Sinologic ha participado en este primer número con un artículo sobre VoIP, y esperamos que no sea el único en el que participamos. La revista ETC es de suscripción gratuita y se puede descargar en formato EPUB y en PDF, aunque también puedes suscribirte y te la envían gratuitamente a casa.